Performance
FoundationDB uses commodity hardware to provide high throughputs and low latencies to your application at a variety of scales.
Scaling
FoundationDB scales linearly with the number of cores in a cluster over a wide range of sizes.
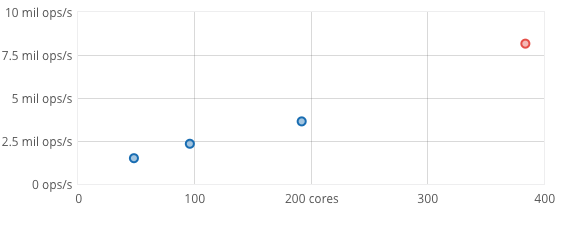
Here, a cluster of commodity hardware scales to 8.2 million operations/sec doing a 90% read and 10% write workload with 16 byte keys and values between 8 and 100 bytes.
The scaling graph uses a 24-machine EC2 c3.8xlarge cluster in which each machine has a 16-core processor. We ran a FoundationDB server process on each core, yielding a 384-process cluster for the largest test, and scaled the cluster down for each smaller test.
Scaling is the ability to efficiently deliver operations at different scales. For FoundationDB, the relevant operations are reads and writes, measured in operations per sec. Scale is measured in the number of processes, which will usually track the number of available cores. FoundationDB offers scalability from partial utilization of a single core on a single machine to full utilization of dozens of powerful multi-core machines in a cluster.
See our known limitations for details about the limits of cluster scalability.
Latency
FoundationDB has low latencies over a broad range of workloads that only increase modestly as the cluster approaches saturation.
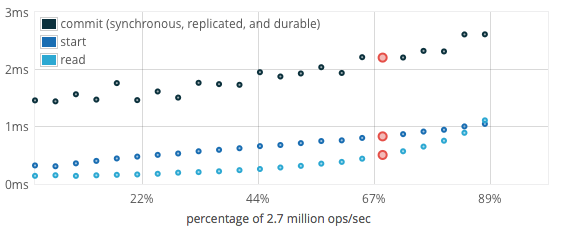
When run at less than 75% load, FoundationDB typically has the following latencies:
Start transaction |
0.3 - 1ms |
Read |
0.1 - 1ms |
Set |
0 (deferred until commit) |
Commit |
1.5 - 2.5ms |
The latency graph uses a 12-machine cluster in which each machine has a 4-core (E3-1240) processor and a single SATA SSD. We ran a FoundationDB server process on each core, yielding a 48-process cluster.
Latency is the time required to complete a given operation. Latencies in FoundationDB are typically measured in milliseconds (ms). Like all systems, FoundationDB operates at low latencies while under low load and increasing latencies as the load approaches the saturation point. FoundationDB is engineered to keep latencies low even at moderate loads. As loads approach saturation, latencies increase as requests are queued up.
For FoundationDB, the significant latencies are those experienced by a FoundationDB client as it prepares and submits a transaction. Writes incur no latency until the transaction is committed. There are three actions within a transaction that do incur latency:
Transaction start. This latency will be experienced as part of the first read in a transaction as the read version is obtained. It will typically be a few milliseconds under moderate load, but under high write loads FoundationDB tries to concentrate most transaction latency here.
Reads. Individual reads should take under 1 ms with moderate loads. If a transaction performs many reads by waiting for each to complete before starting the next, however, these small latencies can add up. You can thus reduce total latency (and potentially conflicts) by doing as many of your reads as possible in parallel. FoundationDB supports non-blocking reads, so it’s easy to perform reads without waiting on them.
Commit. Transactions that perform writes must be committed, and the commit will not succeed until the transaction is durable with full replication. This latency should average under 3 ms with moderate loads. Only a small part of this latency impacts transaction conflicts.
Throughput (per core)
FoundationDB provides good throughput for the full range of read and write workloads, with two fully durable storage engine options.
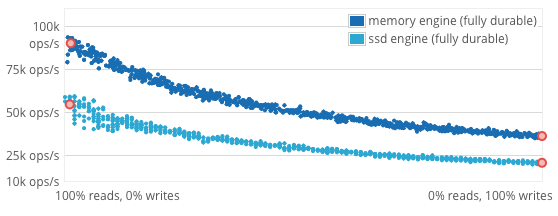
FoundationDB offers two storage engines, optimized for distinct use cases, both of which write to disk before reporting transactions committed. For each storage engine, the graph shows throughput of a single FoundationDB process running on a single core with saturating read/write workloads ranging from 100% reads to 100% writes, all with 16 byte keys and values between 8 and 100 bytes. Throughput for the unmixed workloads is about:
workload |
ssd engine |
memory engine |
|---|---|---|
Reads |
55,000/sec |
90,000/sec |
Writes |
20,000/sec |
35,000/sec |
The throughput graph uses a single FoundationDB server process on a single core (E3-1240).
Throughput is the total number of operations successfully completed by a system in a given period of time. For FoundationDB, we measure throughput in operations, i.e., some mix of read and writes, per second.
The memory engine is optimized for datasets that entirely fit in memory, with secondary storage used for durable writes but not reads. The SSD engine is optimized for datasets that do not entirely fit in memory, with some percentage of reads being served from secondary storage.
Because SATA SSDs are only about 50 times slower than memory, they can be combined with memory to achieve throughputs on the same order of magnitude as memory alone as long as cache-hit rates are reasonable. The SSD engine takes advantage of this property. In contrast, spinning disks are 5,000 times slower than memory and radically degrade throughput as soon as cache hits fall appreciably below 100%.
FoundationDB will only reach maximum throughputs with a highly concurrent workload. In fact, for a given average latency, concurrency is the main driver of throughput.
Concurrency
FoundationDB is designed to achieve great performance under high concurrency from a large number of clients.
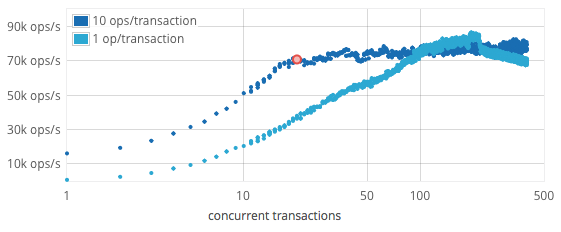
Its asynchronous design allows it to handle very high concurrency, and for a typical workload with 90% reads and 10% writes, maximum throughput is reached at about 200 concurrent operations. This number of operations was achieved with 20 concurrent transactions per FoundationDB process each running 10 operations with 16 byte keys and values between 8 and 100 bytes.
The concurrency graph uses a single FoundationDB server process on a single core (E3-1240).
For a given system, average throughput and latency are related by a ratio known in queuing theory as Little’s Law. The practical application of this law to FoundationDB states:
throughput = outstanding requests / latency
The implication of this relation is that, at a given latency, we can maximize throughput only by concurrently submitting enough outstanding requests. A FoundationDB cluster might have a commit latency of 2 ms and yet be capable of far more than 500 commits per second. In fact, tens of thousands of commits per second are easily achievable. To achieve this rate, there must be hundreds of requests happening concurrently. Not having enough pending requests is the single biggest reason for low performance.
Other Effects
A lot of things affect the simple first-order model of performance you see here. For example:
For short periods, higher write throughputs can be absorbed, giving higher performance and keeping latencies low.
Most workloads’ reads can be cached, giving higher performance.
Adjacently written keys can be written much faster.
Large keys make the storage engine slower.
Large values cost more to read and write than smaller ones.
Not all CPUs are the same speed.
To keep up with the performance modeled above, your disk subsystem will need to do a little over 1 IOPS per write, and about 1 IOPS per (uncached) read.
Network performance tuning at the operating system level can be very important for both latency and throughput, especially in larger clusters.
Running DR and/or backup requires applying each mutation multiple times and then reading those mutations from the database. Using either feature will reduce throughput.
See our known limitations for other considerations which may affect performance.