Unconstrained Scene Generation with Locally Conditioned Radiance Fields, ICCV 2021




Terrance DeVries (Apple),
Miguel Angel Bautista (Apple),
Nitish Srivastava (Apple),
Graham W. Taylor (University of Guelph, Vector Institute),
Joshua M. Susskind (Apple)
Summary
- We introduce Generative Scene Networks (GSN), a generative model which learns to synthesize radiance fields of indoor scenes.
- Decomposing large radiance fields into a collection of many small, locally conditioned radiance fields improves generation quality.
- GSN learns a useful scene prior, which can be leveraged for downstream tasks beyond scene synthesis.
Expand Abstract
*We tackle the challenge of learning a distribution over complex, realistic, indoor scenes. In this paper, we introduce ___Generative Scene Networks___ (GSN), which learns to decompose scenes into a collection of many local radiance fields that can be rendered from a free moving camera. Our model can be used as a prior to generate new scenes, or to complete a scene given only sparse 2D observations. Recent work has shown that generative models of radiance fields can capture properties such as multi-view consistency and view-dependent lighting. However, these models are specialized for constrained viewing of single objects, such as cars or faces. Due to the size and complexity of realistic indoor environments, existing models lack the representational capacity to adequately capture them. Our decomposition scheme scales to larger and more complex scenes while preserving details and diversity, and the learned prior enables high-quality rendering from viewpoints that are significantly different from observed viewpoints. When compared to existing models, GSN produces quantitatively higher-quality scene renderings across several different scene datasets.*Architecture
We follow an adversarial learning framework, where the generator models scenes via their radiance field, and the discriminator attempts to distinguish between images rendered from those radiance fields and images of real scenes. Conceptually, our model decomposes the radiance field of a scene into many small local radiance fields that result from conditioning on a 2D grid of latent codes W. W can be interpreted as a latent floorplan representing the scene.
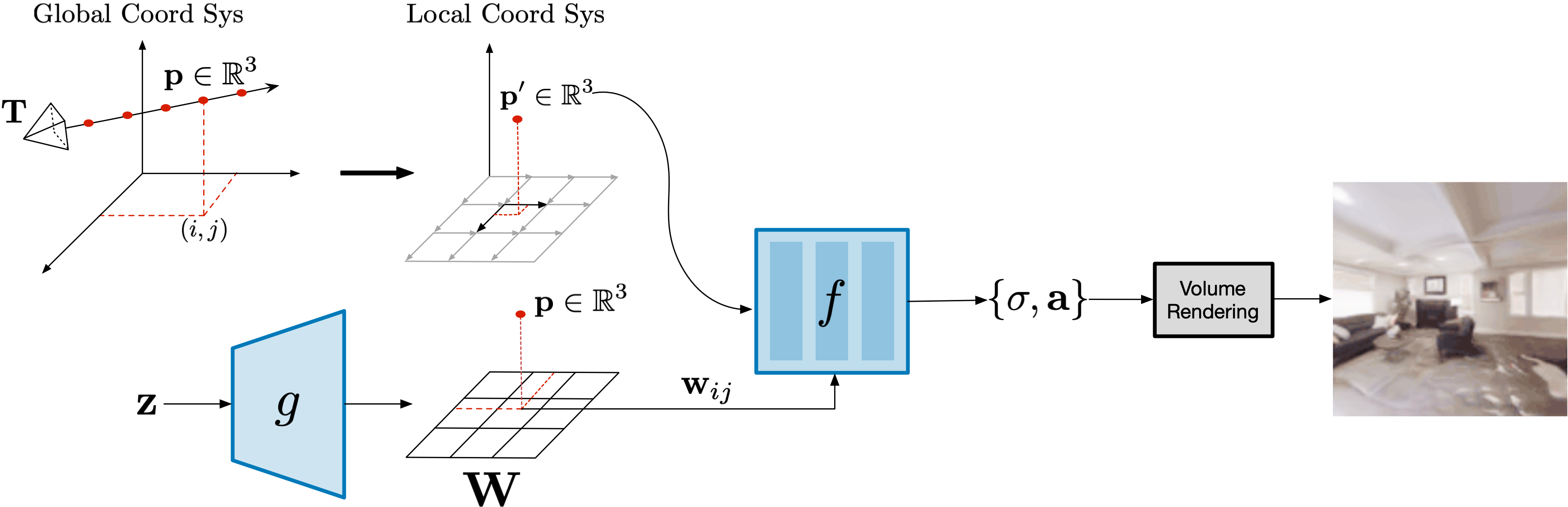
Results
We train GSN on scene level datasets composed of multiple scenes, generating views from a freely moving camera, as opposed to synthesizing views on a small baseline or a viewing sphere.

Small baseline camera movement (previous work)

Freely moving camera (ours)
Scene Generation
After training, we can sample scenes from the learned prior and render them from an arbitrary camera pose, allowing for unconstrained scene exploration.
Sampled scenes
View Synthesis
In addition, we can also use the prior learned by GSN to invert observations and fill in missing parts of the scene. Given source views S we invert GSNs generator to generate a scene radiance field that minimizes a reconstruction error, we then render this radiance field from target camera poses T.

The images highlighted in green are inputs to GSN, images highlighted in blue are predicted views. The top 3 rows show results on training data and the bottom 3 rows show results on a held out test set.
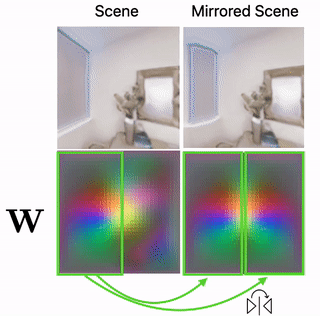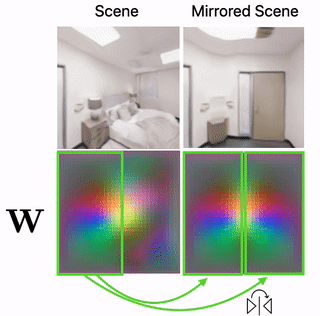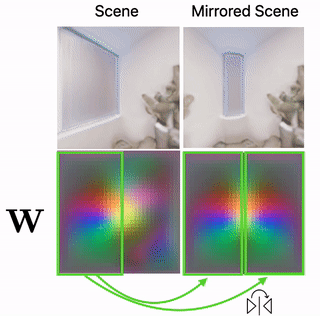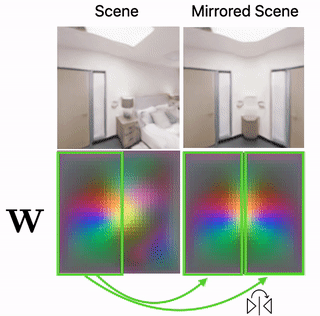
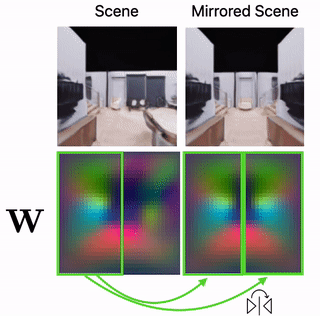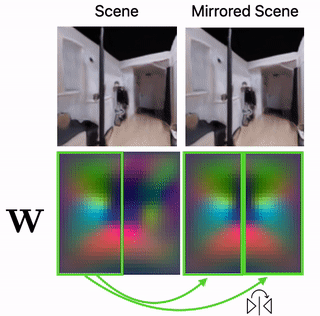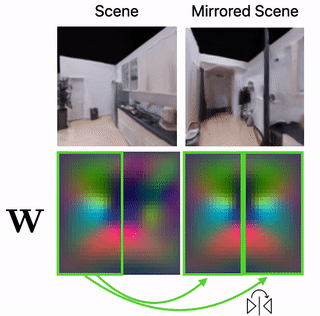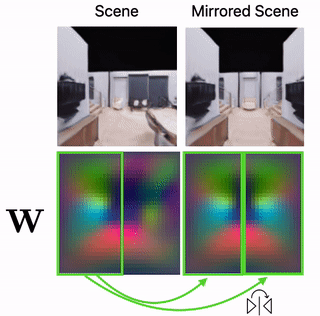
Scene Mirroring
Our learned scene representation W can be used for spatial scene editing. Specifically, we use it to show that we can mirror scenes by mirroring their latent floorplan representation W.
Citation
@article{devries2021unconstrained,
title={Unconstrained Scene Generation with Locally Conditioned Radiance Fields},
author={Terrance DeVries and Miguel Angel Bautista and
Nitish Srivastava and Graham W. Taylor and
Joshua M. Susskind},
journal={arXiv},
year={2021}
}
Source code
Code is available here
Related links
Check out recent related work on making radiance fields generalize to multiple objects/scenes: