DNIKit – Data and Network Introspection Kit#
A Python toolkit for analyzing machine learning models and datasets. DNIKit can:
DNIKit algorithms (also known as introspectors) view data through the eyes of a neural network. They operate using intermediate responses of the networks to provide a unique glimpse of how the network perceives data throughout the different stages of computation.
Getting Started#
Explore the links in the sidebar on the left. Here are some good places to get started:
and see the following DNIKit use case examples.
Examples#
Identify model biases and annotation errors#
The Familiarity introspector can be used to plot the most and least representative data samples for a given set of data samples, which can assist in identifying model biases and annotation errors. For instance, introspecting with a simple CNN model trained on MNIST, and the MNIST dataset, there is a clear predilection for slanted 5’s (top, “most familiar”):

Fives that aren’t slanted, written with a fine-tipped pen, or look like capital S’s are the least “five-like” when compared to the overall dataset (bottom, “least familiar”). In the “least familiar” plot, at the far right of the first row, there is a “J”-like symbol that is not very interpretable as a 5, and we might want to remove it from the dataset. [1]
Familiarity analyzes intermediate network embeddings, rather than final model output. This means it may also be run on models that will be fine-tuned or adapted and were not trained on the target task, like MobileNet, trained on ImageNet. For instance, running Familiarity on data samples with the “deer” label in the CIFAR10 dataset, using responses extracted with this MobileNet model, the results are as follows:
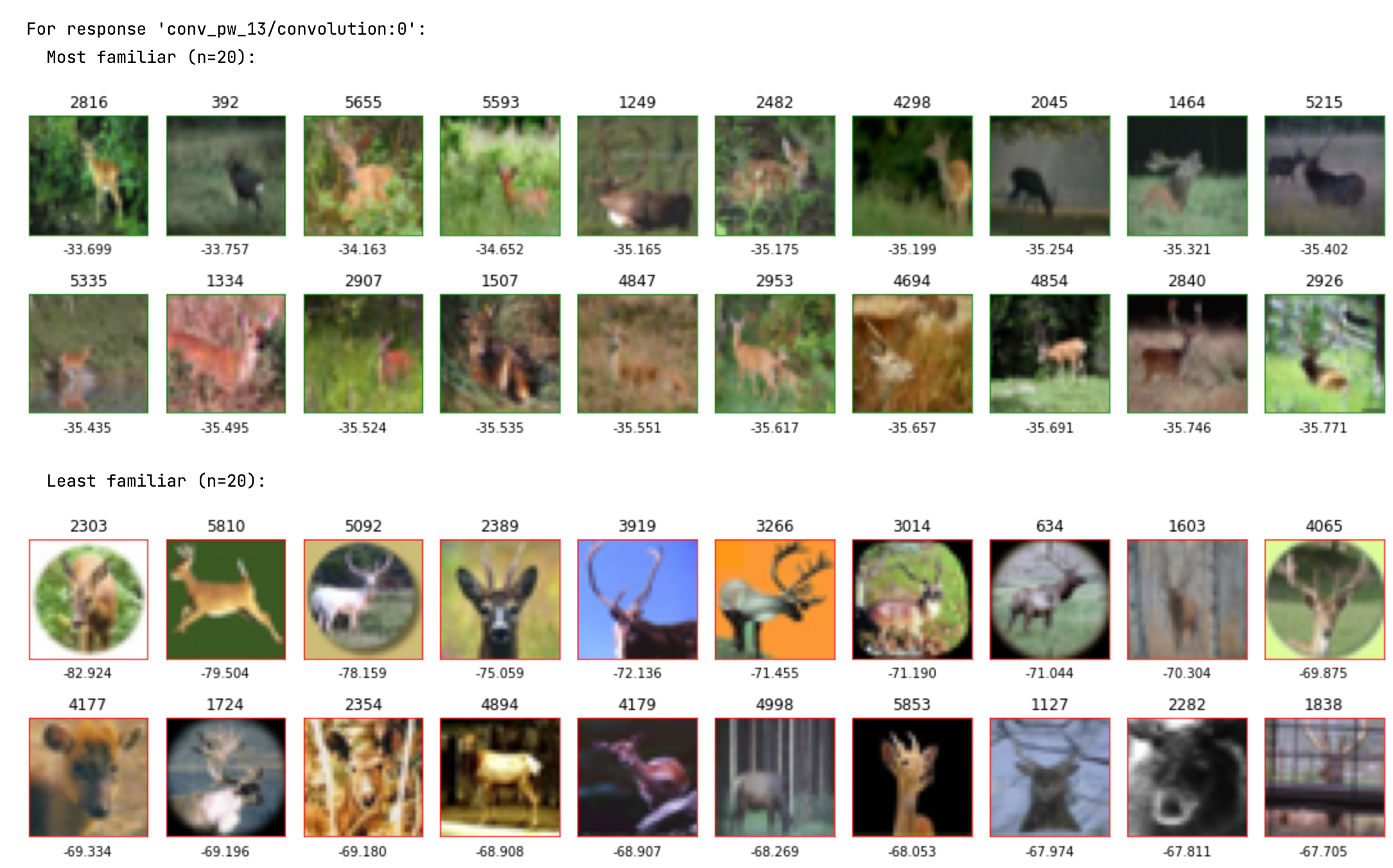
The most representative (most familiar) deer images include scenes with green foliage and coarse textures, while the least representative (least familiar) samples show deer on single-color backgrounds or within circles. To improve diversity within the “deer” data samples, a user might consider collecting more data samples like what are shown in the “least familiar” rows.
Compress a network#
Principal Filter Analysis (PFA) can be used to compress networks without compromising accuracy; e.g., tests on VGG-16 on CIFAR-10, CIFAR-100 and ImageNet actually show that PFA achieves a compression rate of 8x, 3x, and 1.4x with an accuracy gain of 0.4%, 1.4% points, and 2.4% respectively.
For a quick example, let’s use PFA to compress the
Keras library’s example ConvNet
for the MNIST dataset.
The model is trained exactly as specified in a Jupyter notebook,
save the model to disk with model.save("mnist.h5"), then run:
from dnikit.base import pipeline, TrainTestSplitProducer
from dnikit_tensorflow import load_tf_model_from_path
# Load model into DNIKit
dni_model = load_tf_model_from_path('mnist.h5')
# Get Conv2D layer names to request responses from
req_layers = [
name for name in dni_model.response_infos.keys()
if 'conv' in name
]
# Set up pipeline to feed batches of data into model
# :: Note: use the same x_train, y_train, etc.
# :: from the Keras MNIST CNN example code.
mnist = TrainTestSplitProducer(((x_train, y_train), (x_test, y_test)))
responses = pipeline(
mnist,
dni_model(requested_responses=req_layers),
Pooler(dim=(1, 2), method=Pooler.Method.MAX)
)
PFA.introspect can be used to compress the model, estimating new layer sizes:
pfa = PFA.introspect(responses) # introspect!
# Show suggestions for new layer sizes with 'KL' strategy
PFA.show(pfa.get_recipe())

To act on the suggestions, the model is then re-trained with the suggested layer sizes. Note, it’s possible in this step to reuse weights and train from there to get better results, rather than training from scratch. Looking at the suggestions and setting the two Conv2D layers at 21 and 45 filters, respectively, PFA helps achieve a 40% reduction in model size (271 KB vs 450 KB) with no significant cost to accuracy. [2] [3] Please see the PFA paper or doc page for more information about the experiments.
Footnotes