Model Prediction#
After converting a source model to a Core ML model, you can evaluate the Core ML model by verifying that the predictions made by the Core ML model match the predictions made by the source model.
The following example makes predictions for the HousePricer.mlmodel using the predict() method.
import coremltools as ct
# Load the model
model = ct.models.MLModel('HousePricer.mlmodel')
# Make predictions
predictions = model.predict({'bedroom': 1.0, 'bath': 1.0, 'size': 1240})
macOS Required for Model Prediction
For the prediction API, coremltools interacts with the Core ML framework which is available on macOS only. The prediction API is not available on Linux.
However, Core ML models can be imported and executed with TVM, which may provide a way to test Core ML models on non-macOS systems.
Types of Inputs and Outputs#
Core ML supports several feature types for inputs and outputs. The following are two feature types that are commonly used with neural network models:
ArrayFeatureType, which maps to the MLMultiArray Feature Value in SwiftImageFeatureType, which maps to the Image Feature Value in Swift
When using the Core ML model in your Xcode app, use an MLFeatureValue, which wraps an underlying value and bundles it with that value’s type, represented by MLFeatureType.
To evaluate a Core ML model in python using the predict() method, use one of the following inputs:
Learn More About Image Input and Output
To learn how to work with images and achieve better performance and more convenience, see Image Input and Output.
Specifying Compute Units#
If you don’t specify compute units when converting or loading a model, all compute units available on the device are used for execution including the Neural Engine (NE), the CPU, and the graphics processing unit (GPU).
You can control which compute unit the model runs on by setting the compute_units argument when converting a model (with coremltools.convert()) or loading a model (with coremltools.models.MLModel). Calling predict() on the converted or loaded model restricts the model to use only the specific compute units for execution.
For example, the following sets the compute units to CPU only when loading the model:
model = ct.model.MLModel('path/to/the/saved/model.mlmodel', compute_units=ct.ComputeUnit.CPU_ONLY)
Deprecated Flag
In previous versions of coremltools, you would restrict execution to the CPU by specifying the useCPUOnly=True flag. This flag is now deprecated. Instead, use the compute_units parameter .
For more information and values for this parameter, see Set the Compute Units.
Fast Predictions#
A Model can be loaded using the Fast Prediction Optimization Hint. This will prefer the prediction latency at the potential cost of specialization time, memory footprint, and the disk space usage.
model = ct.model.MLModel(
'path/to/the/saved/model.mlmodel',
optimization_hints={ 'specializationStrategy': ct.SpecializationStrategy.FastPrediction }
)
Multi-array Prediction#
A model that takes a MultiArray input requires a NumPy array as an input with the predict() call. For example:
import coremltools as ct
import numpy as np
model = ct.models.MLModel('path/to/the/saved/model.mlmodel')
# Print input description to get input shape.
print(model.get_spec().description.input)
input_shape = (...) # insert correct shape of the input
# Call predict.
output_dict = model.predict({'input_name': np.random.rand(*input_shape)})
Image Prediction#
A model that takes an image input requires a PIL image as an input with the predict() call. For example:
import coremltools as ct
import numpy as np
import PIL.Image
# Load a model whose input type is "Image".
model = ct.models.MLModel('path/to/the/saved/model.mlmodel')
Height = 20 # use the correct input image height
Width = 60 # use the correct input image width
# Scenario 1: load an image from disk.
def load_image(path, resize_to=None):
# resize_to: (Width, Height)
img = PIL.Image.open(path)
if resize_to is not None:
img = img.resize(resize_to, PIL.Image.ANTIALIAS)
img_np = np.array(img).astype(np.float32)
return img_np, img
# Load the image and resize using PIL utilities.
_, img = load_image('/path/to/image.jpg', resize_to=(Width, Height))
out_dict = model.predict({'image': img})
# Scenario 2: load an image from a NumPy array.
shape = (Height, Width, 3) # height x width x RGB
data = np.zeros(shape, dtype=np.uint8)
# manipulate NumPy data
pil_img = PIL.Image.fromarray(data)
out_dict = model.predict({'image': pil_img})
Image Prediction for a Multi-array Model#
If the Core ML model has a MultiArray input type that actually represents a JPEG image, you can still use the JPEG image for the prediction if you first convert the loaded image to a NumPy array, as shown in this example:
Height = 20 # use the correct input image height
Width = 60 # use the correct input image width
# Assumption: the mlmodel's input is of type MultiArray and of shape (1, 3, Height, Width).
model_expected_input_shape = (1, 3, Height, Width) # depending on the model description, this could be (3, Height, Width)
# Load the model.
model = coremltools.models.MLModel('path/to/the/saved/model.mlmodel')
def load_image_as_numpy_array(path, resize_to=None):
# resize_to: (Width, Height)
img = PIL.Image.open(path)
if resize_to is not None:
img = img.resize(resize_to, PIL.Image.ANTIALIAS)
img_np = np.array(img).astype(np.float32) # shape of this numpy array is (Height, Width, 3)
return img_np
# Load the image and resize using PIL utilities.
img_as_np_array = load_image_as_numpy_array('/path/to/image.jpg', resize_to=(Width, Height)) # shape (Height, Width, 3)
# PIL returns an image in the format in which the channel dimension is in the end,
# which is different than Core ML's input format, so that needs to be modified.
img_as_np_array = np.transpose(img_as_np_array, (2,0,1)) # shape (3, Height, Width)
# Add the batch dimension if the model description has it.
img_as_np_array = np.reshape(img_as_np_array, model_expected_input_shape)
# Now call predict.
out_dict = model.predict({'image': img_as_np_array})
Using Compiled Python Models for Prediction#
You can use a compiled Core ML model (CompiledMLModel) rather than MLModel for making predictions. For large models, using a compiled model can save considerable time in initializing the model.
For example, Stable Diffusion, adopted by a vibrant community of artists and developers, enables the creation of unprecedented visuals from a text prompt. When using Core ML Stable Diffusion, you can speed up the load time after the initial load by first copying and storing the location of the mlmodelc compiled model to a fixed location, and then initializing the model from that location.
Note
You can’t modify a compiled model like you can an MLModel loaded from a non-compiled mlpackage model file.
Why Use a Compiled Model?#
When you initialize a model using (in Python) model=ct.models.MLModel("model.mlpackge"), the Core ML Framework is invoked and the following steps occur, as shown in the following diagram.
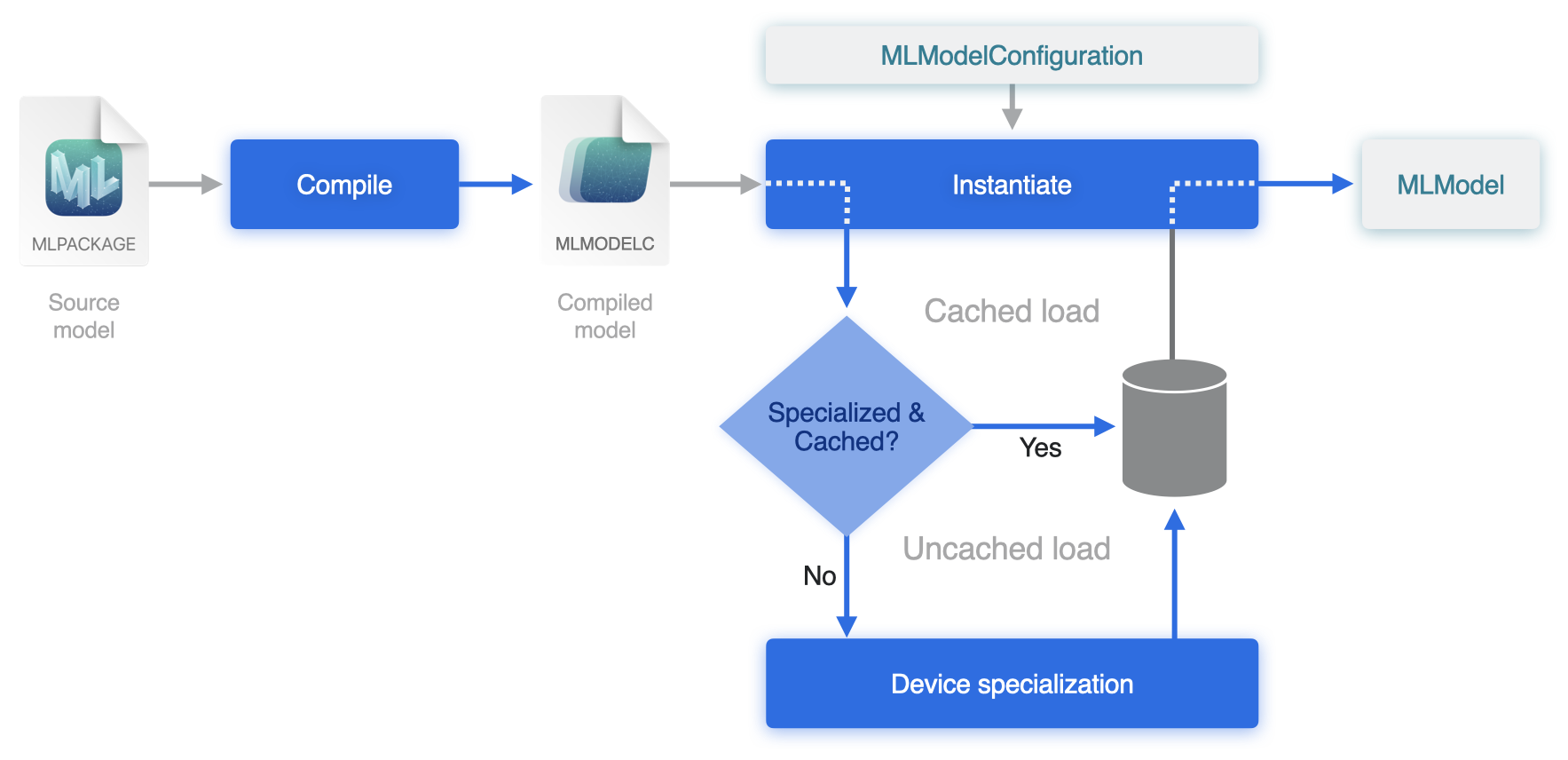
This diagram is from Improve Core ML integration with async prediction, presented at the Apple 2023 World Wide Developer Conference.#
The
mlpackageis compiled into a file with extensionmlmodelc. This step is usually very fast.The compiled model is then instantiated using the specified
compute_unitscaptured in the MLModelConfiguration config.During instantiation, another compilation occurs for backend device specialization, such as for the Neural Engine (NE), which may take a few seconds or even minutes for large models.
This device specialization step creates the final compiled asset ready to be run. This final compiled model is cached so that the expensive device optimization process does not need to run again. The cache entry is linked to the full file system path of the mlmodelc folder.
As you create an MLModel object in Python using an mlpackage, it uses a temporary directory in a new location to place the mlmodelc folder. The mlmodelc file is then deleted after you have made predictions and the Python process has ended.
The next time you start a new Python process and create an MLModel, the compilation to mlmodelc and the subsequent device specialization occurs again. The cached set can’t be used again, because the location of mlmodelc has changed.
By storing the mlmodelc file to a fixed location first, and then initializing the MLModel from that location, you can make sure that the cache model generated remains active for subsequent loads, thereby making them faster. Let’s see how you would do that in code.
Predict From the Compiled Model#
To use a compiled model file, follow these steps:
Load a saved MLModel, or convert a model from a training framework (such as TensorFlow or PyTorch).
For instructions on converting a model, see Load and Convert Model Workflow. This example uses the regnet_y_128fg torchvision model and assumes that you have already converted it to a Core ML
mlpackage.Get the compiled model directory by calling its
get_compiled_model_pathmethod.For example, the following code snippet loads a saved MLModel (
"regnet_y_128gf.mlpackage") and gets the compiled path:mlmodel = ct.models.MLModel("regnet_y_128gf.mlpackage") compiled_model_path = mlmodel.get_compiled_model_path()
The returned directory in
compiled_model_pathis only temporary. Copy that directory to a new persistent location (as in the following example,regnet_y_128gfwith the extension.mlmodelcin the same directory) using theshutil.copytree()method. You can then use CompiledMLModel to load the compiled model from"regnet_y_128gf.mlmodelc":from shutil import copytree copytree(compiled_model_path, "regnet_y_128gf.mlmodelc", dirs_exist_ok=True) mlmodel = ct.models.CompiledMLModel("regnet_y_128gf.mlmodelc")
This step includes compiling for device specialization. Therefore, the first load can still take a long time. However, since the location of the
mlmodelcfolder is fixed, the cache is able to work, so subsequent calls to model using CompiledMLModel are quick.For each prediction, use the
mlmodelobject to take advantage of this caching:prediction = mlmodel.predict({'x': 2})
With most large models, it should be very quick to use the compiled model again after the first call.
Timing Example#
This example demonstrates timing differences with calling a large model. The results are based on running the example on a MacBook Pro M1 Max with macOS Sonoma. Your timing results will vary depending on your system configuration and other factors.
The following code snippet converts a relatively large model from torchvision:
import coremltools as ct
import torchvision
import torch
from shutil import copytree
torch_model = torchvision.models.regnet_y_128gf()
torch_model.eval()
example_input = torch.rand(1, 3, 224, 224)
traced_model = torch.jit.trace(torch_model, example_input)
mlmodel = ct.convert(traced_model,
inputs=[ct.TensorType(shape=example_input.shape)],
)
mlmodel.save("regnet_y_128gf.mlpackage")
# save the mlmodelc
compiled_model_path = mlmodel.get_compiled_model_path()
copytree(compiled_model_path, "regnet_y_128gf.mlmodelc", dirs_exist_ok=True)
The following code snippet measures load time:
from time import perf_counter
tick = perf_counter()
mlmodel = ct.models.MLModel("regnet_y_128gf.mlpackage")
print("time taken to load using ct.models.MLModel: {:.1f} secs".format(perf_counter() - tick))
tick = perf_counter()
mlmodel = ct.models.MLModel("regnet_y_128gf.mlpackage")
print("time taken to load using ct.models.MLModel: {:.1f} secs".format(perf_counter() - tick))
tick = perf_counter()
mlmodel = ct.models.CompiledMLModel("regnet_y_128gf.mlmodelc")
print("time taken to load using ct.models.CompiledMLModel: {:.1f} secs".format(perf_counter() - tick))
tick = perf_counter()
mlmodel = ct.models.CompiledMLModel("regnet_y_128gf.mlmodelc")
print("time taken to load using ct.models.CompiledMLModel: {:.1f} secs".format(perf_counter() - tick))
Running the code produces the following output:
time taken to load using ct.models.MLModel: 15.3 secs
time taken to load using ct.models.MLModel: 17.7 secs
time taken to load using ct.models.CompiledMLModel: 14.7 secs
time taken to load using ct.models.CompiledMLModel: 0.1 secs
These results show that it takes relatively the same time to load an MLModel after the first load, while loading a CompiledMLModel takes much less time after the first load.