Comparing ML Programs and Neural Networks#
As ML models evolve in sophistication and complexity, their representations are also evolving to describe how they work. ML programs are models that are represented as operations in code. The ML program model type is the foundation for future Core ML improvements.
A few of the major differences between a neural network and an ML program are as follows:
Neural Network |
ML Program |
|---|---|
Layers with a computational graph representation |
Operations with a programmatic representation |
Weights embedded in layers |
Weights decoupled and serialized |
Intermediate tensor type implicit |
Intermediate tensor type explicit |
Limited control over precision |
More granular control over precision |
ML Program Benefits#
Converting to an ML program provides the following advantages over converting to a neural network:
Typed execution for control of numeric precision:
An ML program defines types for the intermediate tensors that are produced by one segment of the model and consumed by another. The ML program runtime respects these specified types as the minimum compute precision. As a result, you can easily control the precision when you convert the model. By comparison, the neural network precision type is tied to the compute unit. For details, see Typed Execution.
GPU runtime for float 32 precision:
ML programs use a GPU runtime that is backed by the Metal Performance Shaders Graph framework. While the GPU with neural networks supports only float 16 precision at runtime, this execution path supports both float 16 and float 32 precision. This path also provides performance improvements, especially for newer devices.
More efficient compiling:
Since ML programs do not store weights in the protobuf file format, the models are more memory-efficient to compile. You can significantly improve performance by using Core ML’s on-device compilation API. For details, see Downloading and Compiling a Model on the User’s Device.
Model Representations#
An mlprogram model type represents a neural network in a different way than the original neuralnetwork model type, and the Core ML framework uses different runtimes when executing them.
There are several ways to represent a deep learning model. At a foundational level, models can be represented as a set of mathematical equations (as shown in the left side of the following figure), which is how they are often described in a machine learning course for beginners.
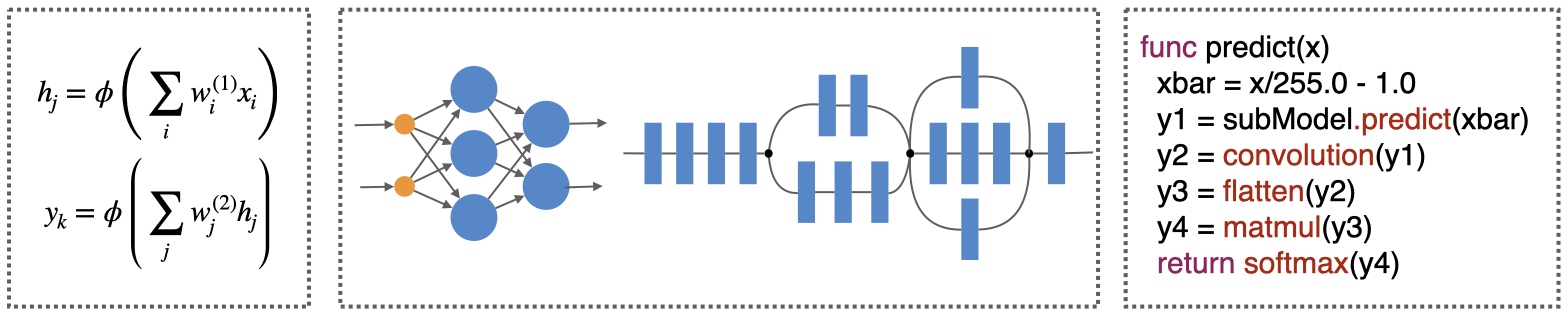
Three ways to represent a deep learning model.#
To express a neural network, the mathematical descriptions are often abstracted into a computational graph, which is a more concise and scalable representation (as shown in the center of the previous figure). A computational graph is a directed graph in which computational layers connect to each other — the input feeds into the source layers and undergoes a series of mathematical transformations to generate the outputs through the sink layers.
At the center of the Core ML NeuralNetwork are the layers that form the nodes of the graph. There are many different types of layers, and each describes a particular mathematical operation. Each layer specifies its input and output names, which are the edges of the graph. Connections are established by matching an output name of a layer to another layer’s input name.
Although the graphical representation is useful for understanding and visualization, the graphs are actually special kinds of programs. A neural network is just like any other program and can be directly represented and stored in a code-like form (as shown in the right side of the previous figure). By representing the model as code, the ML program model provides more flexibility in defining neural networks by incorporating programmatic features such as functions, blocks, control flow, and strongly typed variables.
Differences in Detail#
An ML program differs from a neural network in the following ways:
Ops vs. layers:
An ML Program consists of a main function, which includes one or more blocks. Each block consists of a series of operations (“ops” for short), which are versioned as a set (“opset” for short).
While the layers in a neural network are fully specified in the protobuf serialization file format itself (
Neuralnetwork.proto), the supported ops for an ML program are specified in MIL ops/defs (see the MIL Ops Reference), not in MIL proto messages.Inputs without parameters:
A neural network layer distinguishes between the inputs and the parameters comprised of trained weights and other constants. By comparison, an ML program op has only inputs. (An exception is the
constop which has attributes.) All the inputs are named, so their position is irrelevant. Some of the inputs are constrained to be constants.Variables are typed:
An ML program is typed (for details, see Typed Execution). The inputs and outputs of an op are called variables (“vars” for short). Each var has a type and shape associated with it.
Weights are serialized separately:
The weights for an ML program are serialized outside of the protobuf format. Since the architecture and weights are separated, an ML program can be saved only as a Core ML model package. By comparison, neural networks save its entire representation in a single protobuf file and therefore can be saved as either an
.mlmodelfile or as an.mlpackagemodel package.
To see the ML program representation that is executed, compile a model package of type mlprogram to the mlmodelc archive. You can then find the model.mil file inside the contents, which is the ML program expressed in a text format. To compile an .mlpackage, either compile your Xcode project with the .mlpackage added to it, or execute the following on the command line, which places the compiled archive in the current working directory:
xcrun coremlcompiler compile model.mlpackage .
While the new ML program model type supports most of the functionality supported by neural networks, the following components are not yet supported. If you are using one of these features, you may want to continue to use the neural network format:
-
You can still get the benefit of the ML program runtime by using a
pipelineof the ML program, followed by a neural network consisting of just the updatable portion. Custom operators for neural networks, and your own Swift implementations:
While custom layers may be useful for new layer types, in most cases composite operators built using the MIL builder library are sufficient for converter to handle unsupported layer types. Composite layers, which are built with existing layers, perform better than custom operators and work seamlessly with both neural network and ML program model types.
ML Programs and MIL#
ML program refers to the model type and the language in which they are described is referred to as the Model Intermediate Language (MIL). MIL was introduced with coremltools version 4 as an internal intermediate representation (IR) in the converter stack.
Core ML model support
In addition to ML programs and neural networks, Core ML supports several other model types including trees, support vector machines (SVMs), and general linear models (GLMs).
MIL enables the unification of TensorFlow 1, TensorFlow 2, and PyTorch converters through the Unified Conversion API. The converter works as follows:
The beginning representation (TensorFlow or PyTorch), referred to as the “frontend”, is converted to a Python MIL object with TensorFlow/PyTorch centric MIL opsets. This is then simplified by frontend specific passes.
The result is translated into the common MIL intermediate representation (IR).
MIL is simplified through a sequence of passes.
Finally, MIL is translated into one of the backends for serialization on disk. In coremltools version 4, the backend was
neuralnetwork. In subsequent versionsmlprogramis available as another backend.
The MIL IR for the neuralnetwork model type must be further converted to the NeuralNetwork specification. By comparison, the translation to the ML program specification is straightforward because the same internal MIL Python object is converted to the protobuf format (MIL.proto). The opset of ML program is identical to the ops available in the MIL builder. For details, see the MIL Ops Reference and the Python source code.