Typed Execution#
A model’s compute precision impacts its performance and numerical accuracy, which may impact the user experience of apps using the model. Core ML models saved as ML programs or neural networks execute with either float 32 or float 16 precision.
This page describes how the precision is determined by the runtime during execution of either type of model. The ability to choose this precision can give you more flexible control over computations and performance.
While its useful to understand how the system works, you do not need a complete understanding of the runtime to get your app working optimally with Core ML. In most cases you do not have to take any special action, either during model conversion with coremltools, or during model prediction in your app with the Core ML framework. The defaults picked by coremltools and the Core ML framework work well with most models and are picked to optimize the performance of your model.
Choosing the Appropriate Precision#
Whether you are using neural networks or ML programs, the defaults for conversion and prediction are picked to execute the model in the most performant way. This typically means that portions of your model will run in float 16 precision. This is fine for a majority of machine learning models, since they typically work well with float 16 precision during inference. Higher float 32 precision is usually required only during training.
In some cases the mismatch between the source model trained using float 32 precision and the Core ML model is large enough to significantly affect the user experience. In this case, you would typically want to disable float 16 precision and execute the model with float 32 precision.
If you use convert_to="neuralnetwork" with the convert() method, the precision is tied to the compute unit used for execution, as described in the following section. The CPU guarantees float 32 precision, so you can use the .cpuOnly property in your app’s Swift code when loading the model to enforce the higher precision.
The model format for convert(), by default, is an ML program, which gives you more flexibility. You can set a compute precision of float 32 during the conversion process by using the compute_precision setting, as shown in the following example:
import coremltools as ct
model = ct.convert(source_model,
compute_precision=ct.precision.FLOAT32)
This example produces a float 32 typed Core ML model that executes in float 32 precision irrespective of the value of the MLComputeUnit.
Neural Network Untyped Tensors#
A neural network has explicitly typed model inputs and outputs, but does not define the types of intermediate tensors that are produced by one layer and consumed by another. Instead, the intermediate tensors are automatically typed at runtime by the compute unit responsible for executing the layer producing them.

A sample Core ML model description, as shown in Xcode. The input and output of the model are typed.#
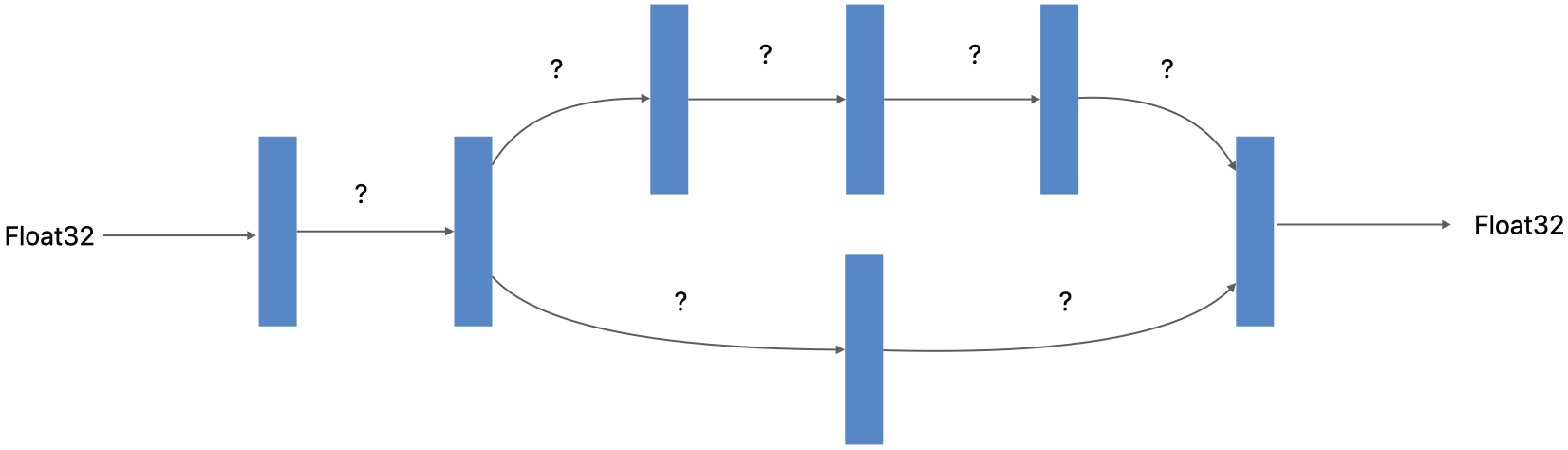
A neural network does not define the types of intermediate tensors that are produced by one layer and consumed by another.#
The Core ML runtime dynamically partitions the network graph into sections for the Neural Engine (NE), GPU, and CPU, and each unit executes its section of the network using its native type to maximize its performance and the model’s overall performance. The GPU and NE use float 16 precision, and the CPU uses float 32. The execution precision varies based on the hardware and software versions, since the partitioning of the graph varies with hardware and software.
You have some control over numeric precision by configuring the set of allowed compute units when converting the model (such as All, CPU&GPU, or CPUOnly), as shown in following chart:
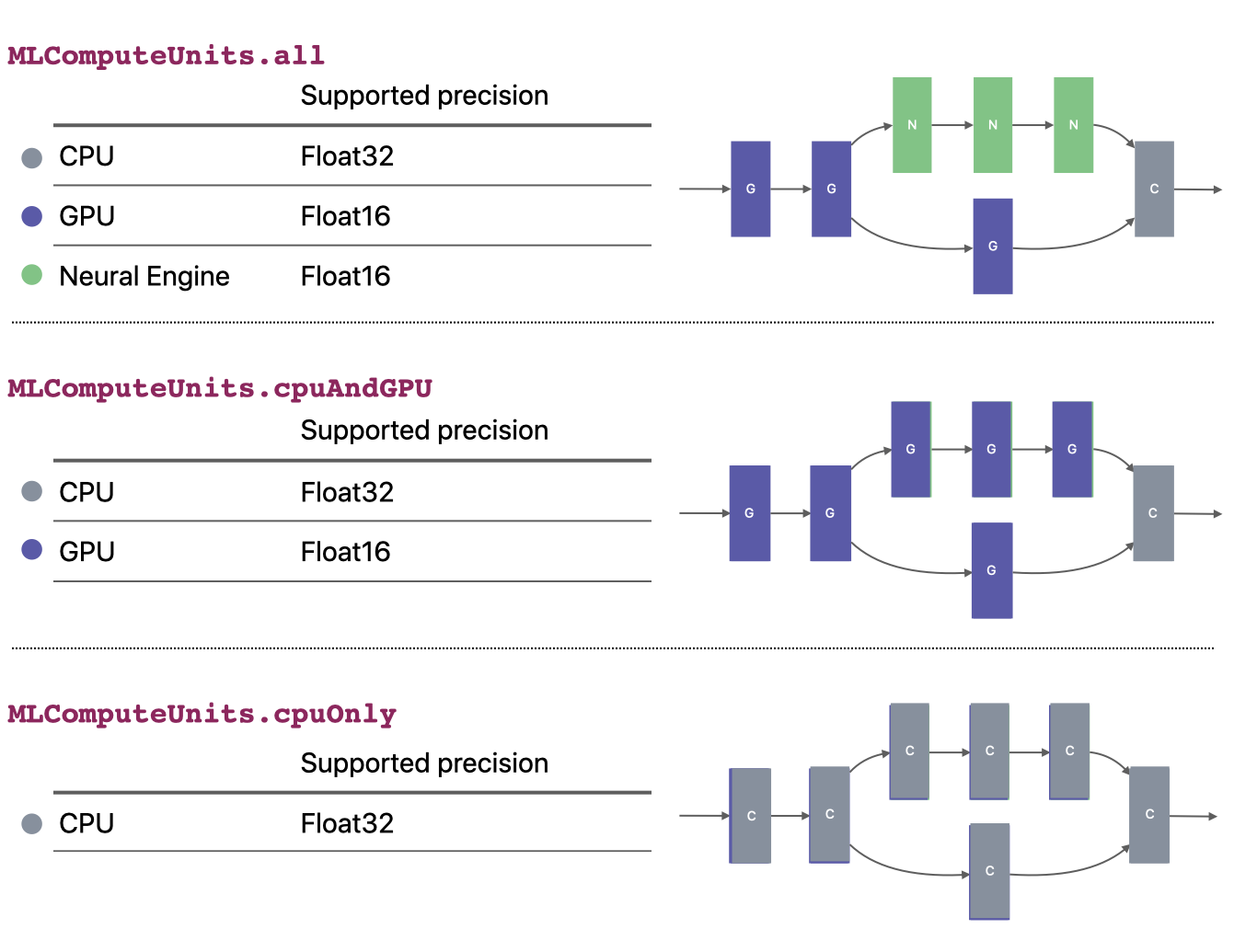
Controlling numeric precision by configuring the set of allowed compute units when converting the model.#
For example, for float 32 precision, the only guaranteed path is to use CPUOnly, which executes entirely on the CPU with float 32 precision. This CPU-only configuration would apply to the model as a whole, and may not provide the best performance.
ML Program Typed Tensors#
ML programs describe a neural network in a code style in which all variables in the program are strongly typed. In contrast to a neural network model, the types of all the intermediate tensors of an ML program are specified in the model itself.
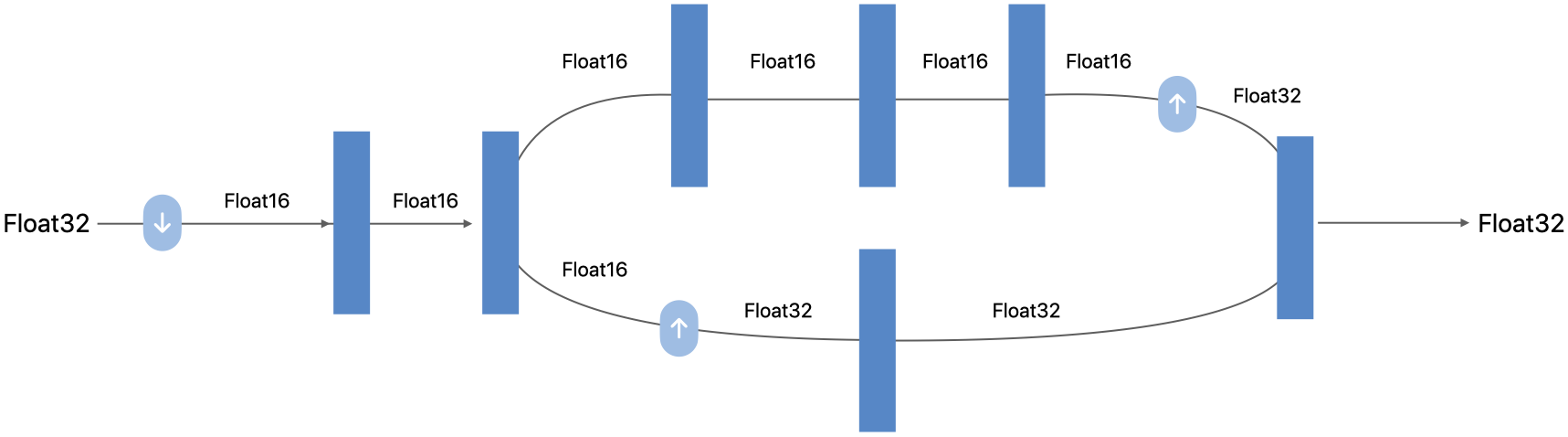
In an ML program, the types of all the intermediate tensors are specified in the model itself.#
An ML program uses the same automatic partitioning scheme that neural networks use to distribute work to the NE, GPU, and CPU. However, the types of the tensors add an additional constraint. The runtime respects the explicit types as the minimum precision, and will not reduce the precision.
For example, a float 32 typed model will only ever run with float 32 precision. A float 16 typed model may run with float 32 precision as well, depending on the availability of the float 16 version of the op, which in turn may depend on the hardware and software versions. With an ML program, the precision and compute engine are independent of each other.
The ML program runtime supports an expanded set of precisions on the backend engines. All of the ops supported on the GPU runtime are now equally supported in float 16 and float 32 precisions. As a result, a float 32 model saved as an ML program need not be restricted to run only on the CPU. In addition, a few selected ops, such as convolution, are also available with float 16 precision on the CPU, and on newer hardware, it can provide further acceleration.
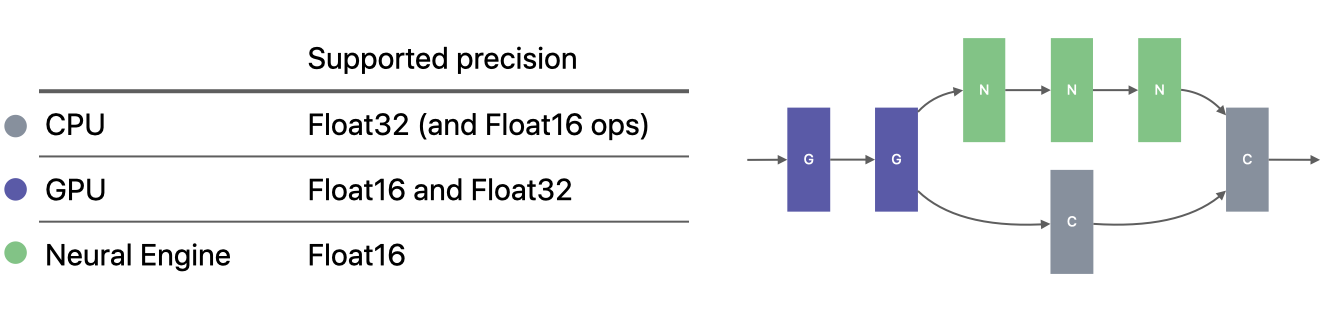
The ML program runtime supports an expanded set of precisions on the backend engines.#
By default, an ML program produced by the converter is typed in float 16 precision, and run with the default configuration that uses all compute units (similar to the default neural network).
For models sensitive to precision, you can set the precision to float 32 during conversion by using the compute_precision=coremltools.precision.FLOAT32 flag with the convert() method. Such a model is guaranteed to run with float 32 precision on all hardware and software versions. Unlike a neural network, the float 32 typed ML program will run on a CPU as well as the GPU. Only the NE is barred as a compute unit when a model is typed with float 32 precision.
With an ML program, you can even mix and match precision support within a single compute unit, such as the CPU or GPU. If you need float 32 precision for specific layers instead of the entire model, you can selectively preserve float 32 tensor types by using the compute_precision=ct.transform.Float16ComputePrecision() transform during model conversion.