Palettization Overview#
Palettization, also referred to as weight clustering, compresses a model by clustering the model’s float weights and creating a lookup table (LUT) of centroids, and then storing the original weight values with indices pointing to the entries in the LUT.
Weights with similar values are grouped together and represented using the value of the cluster centroid they belong to, as shown in the following figure. The original weight matrix is converted to an index table in which each element points to the corresponding cluster center.
N={1,2,3,4,6,8} are supported, where N is the number of bits used for palettization.
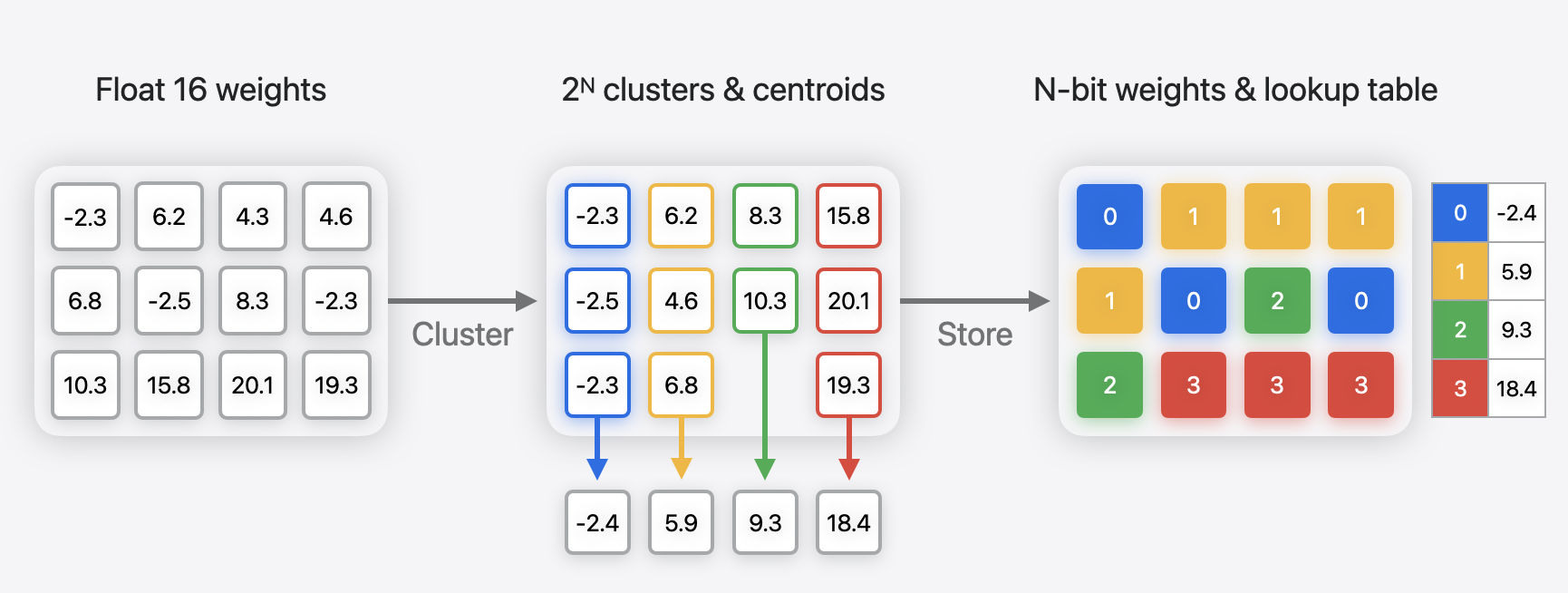
Non-uniform lowering of precision using clustering#
Granularity#
The figure above shows what is referred to as per_tensor granularity, where the entire tensor shares a single LUT. This can lead to high approximation error for large matrices.
Starting with iOS18/macOS15, a mode called per_grouped_channel is available. It allows a group of channels, specified by the parameter group_size, to share a single LUT, thereby having multiple LUTs for the whole weight matrix. For example, a weight of shape (1024, 1024), with group_size=16, will have 64 LUTs.
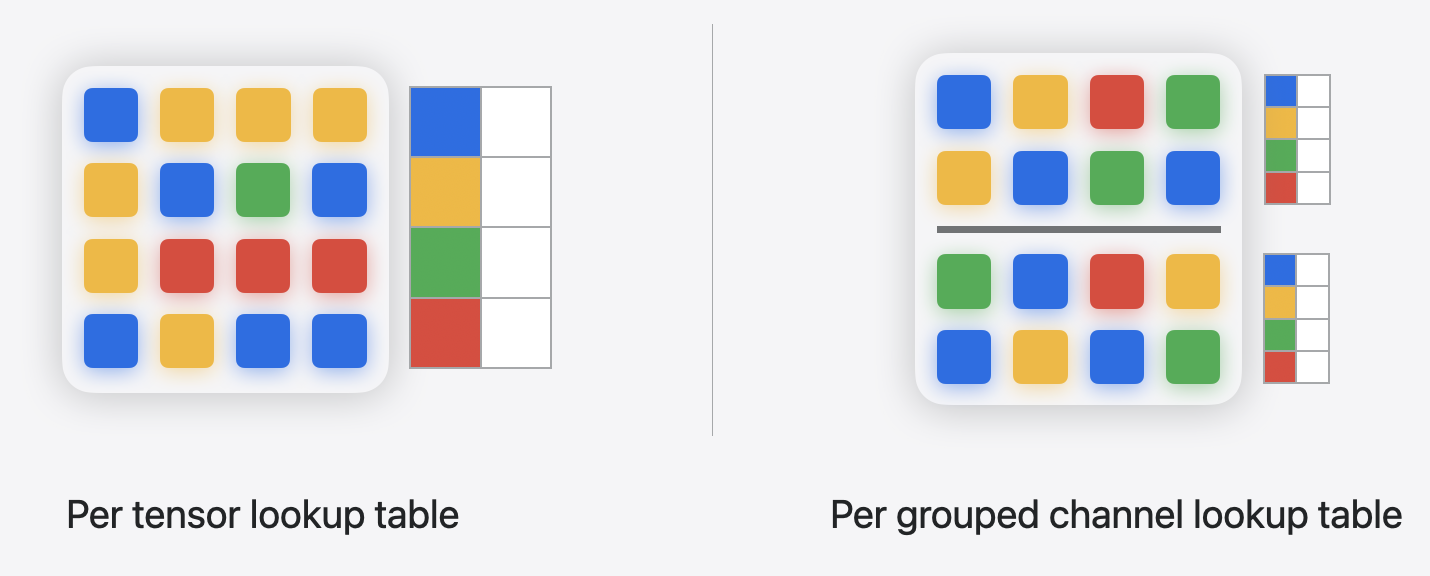
Palettization granularity#
Per-channel scale#
When this mode is enabled, weights are normalized along the output channels using per-channel scales before being palettized.
Vector Palettization#
Cluster centroids can be scalar or vector values. This can be configured with cluster_dim, which by default is set to 1, indicating scalar palettization.
When cluster_dim > 1, it indicates 2-D clustering, and each cluster_dim length of weight vectors along the output channel are palettized using the same 2-D centroid. This is called vector palettization.
Quantizing the LUT#
The values in LUT are by default float. However, starting from iOS18/macOS15, the LUT can be of stored in 8-bit precision as well, for further compression.
Feature Availability
Palettized weight representation for Core ML mlprogram models is available in iOS16/macOS13/watchOS9/tvOS16 and newer deployment target formats.