Palettization Overview#
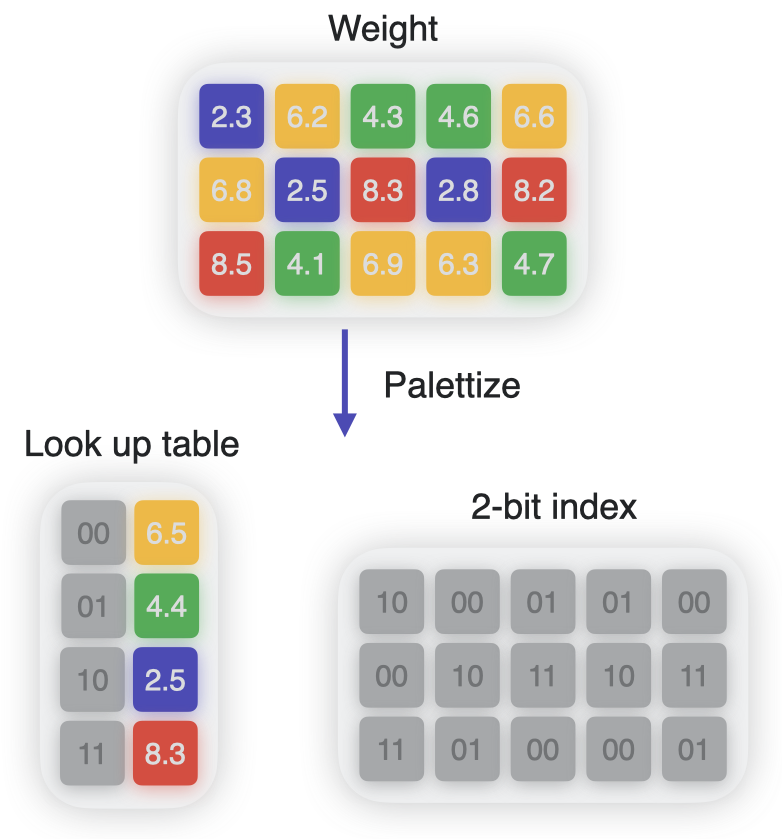
Palettization, also referred to as weight clustering, compresses a model by clustering the model’s float weights, and creating a lookup table (LUT) of centroids, and then storing the original weight values with indices pointing to the entries in the LUT.
Weights with similar values are grouped together and represented using the value of the cluster centroid they belong to, as shown in the following figure. The original weight matrix is converted to an index table in which each element points to the corresponding cluster center.
Non-uniform lowering of precision using clustering.#
Impact on Model Size#
The previous figure shows 4 clusters. Each weight is represented using 2 bits, achieving 8x compression over float16. The number of unique cluster centers used to represent the weights is equal to 2 to the power of n, where n is the number of bits used for palettization. Thus, 4-bit palettization means you can have 16 clusters.
Impact on Latency and Compute Unit Considerations#
Since palettization reduces the size of each weight value, the amount of data to be moved is reduced during prediction. This can lead to benefits in memory-bottlenecked models. Note that this latency advantage is available only when palettized weights are loaded and are decompressed “just in time” of computation. Starting with iOS17/macOS14, this is more likely to happen for models running primarily on the Neural Engine backend.
Feature Availability
Palettized weight representation for Core ML mlprogram models is available in iOS16/macOS13/watchOS9/tvOS16 and newer deployment target formats.