Quantization Overview#
Quantization refers to the process of reducing the number of bits that represent a number. This process casts values from float type to an integer type that uses fewer bits.
How Quantization Works#
Linear quantization, also known as affine quantization, achieves this process by mapping the range of float values to a quantized range, such as the range for 8-bit integers [-127, 128], and interpolating linearly.
This mapping is expressed by the following mathematical equations:
# process of dequantizing weights:
w_unquantized = scale * (w_quantized - zero_point)
# process of quantizing weights:
w_quantized = clip(round(w_unquantized/scale) + zero_point)
In the above equations, w_unquantized and scale are of type float, and w_quantized and zero_point (also called quantization bias, or offset) are of type either int8 or uint8.
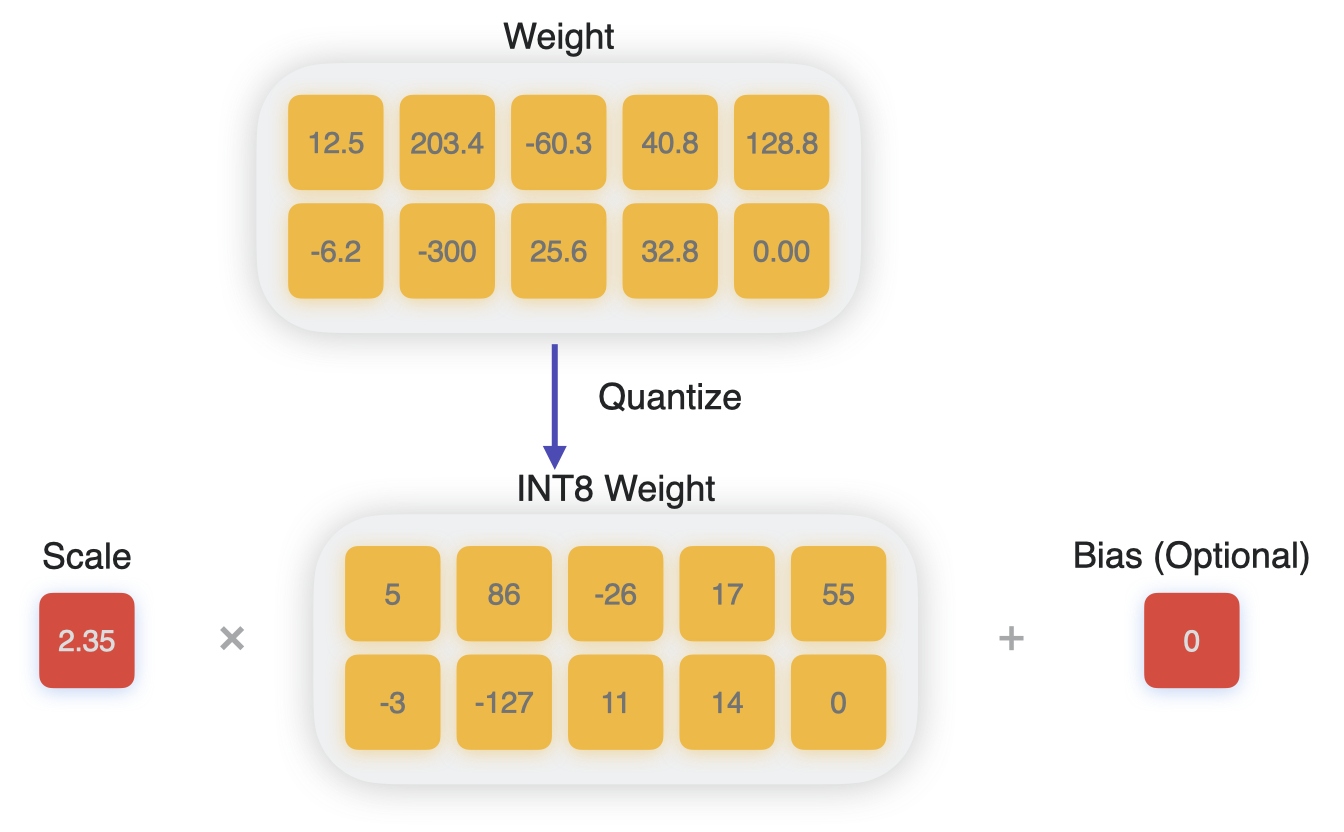
Process of quantizing to int8.#
Symmetric Quantization#
When quantization is performed, constraining the zero_point to be zero is referred to as symmetric quantization. In this case, the quantization and dequantization operations are further simplified. This is the default mode used by Core ML Tools.
Per-Channel Scales#
Rather than computing a single float scale value for the whole tensor (a mode called per-tensor), it is typical to instead use a scale factor for each outer dimension (also referred to as the output channel dimension) of the weight tensor. This is commonly termed as having per-channel scales. In most cases the scale is a vector (the default for Core ML Tools), which reduces the overall quantization error.
Activation Quantization#
Unlike the Pruning or Palettization compression schemes that compress only weights, for 8-bit quantization, activations of the network can also be quantized with their own scale factors.
Activations are quantized using per-tensor mode. During the process of training-time quantization, the values of intermediate activations are observed and their max and min values are used to compute the quantization scales, which are stored during inference. Quantizing the intermediate tensors may help in inference of networks that are bottlenecked by memory bandwidth due to large activations.
Impact on Model Size#
Since 8 bits are used to represent weights, quantization can reduce your model size by 50% compared to float16 storage precision. In reality, the exact compression ratio will be slightly less than 2, since some extra memory needs to be allocated to store the per-channel scale values.
Impact on Latency and Compute Unit Considerations#
Since quantization reduces the size of each weight value, the amount of data to be moved is reduced during prediction. This can lead to benefits with memory-bottlenecked models.
This latency advantage is available only when quantized weights are loaded from memory and are decompressed “just in time” of computation. Starting with iOS17/macOS14, this is more likely to happen for models running primarily on the Neural Engine (NE) backend.
Quantizing the activations may further ease this memory pressure and may lead to more gains when compared to weight-only quantization. However, with activation quantization, you may observe a considerable slowdown in inference for the compute units (CPU and sometimes GPU) that employ load-time weight decompression, since activations are not known at load time, and they need to be decompressed at runtime, slowing down the inference. Therefore it is recommended to use activation quantization only when your model is fully or mostly running on the Neural Engine.
In newer hardware, e.g. iPhone 15 pro (A17 pro), there is increased int8-int8 compute available on NE, compared to previous versions. Hence, activation and weight quantization for networks running on NE can give even more latency gains, as seen in the examples in the performance impact section.
Feature Availability
8-bit quantized weight representations for Core ML mlprogram models is available in iOS16/macOS13/watchOS9/tvOS16 and newer deployment target formats. Activation quantization is available in iOS17/macOS14/watchOS10/tvOS10.